
使用 stat 统计分析异常流量
watch 命令提供了细粒度的观察视角,在分析单个请求响应维度的问题上十分有用。然而考虑到一些问题场景:
- 我的 HTTP 请求慢了,是所有服务端都慢了,还是某一个服务端慢了?
- 有人对我负责的 Redis 发送 get 请求,导致机器带宽被占满,是哪一个客户端 ip 造成的?
stat 命令用于解决这种需要分析大量请求响应才能得出结论的问题。
如何使用 stat 命令
使用 stat 命令非常简单,你只需要确定 你关心的指标是什么?
以上述的这个问题为例:"我的 HTTP 请求慢了,是所有服务端都慢了,还是某一个服务端慢了?",在这里我们关心的是 服务端的响应时间 这个指标。
所以可以输入如下的命令:
./kyanos stat --metric total-time --group-by remote-ip指定 metric 选项为 total-time 代表我们需要统计的指标是请求响应的总耗时,指定 group-by 选项为 remote-ip ,代表我们需要观察的响应时间是每个 remote-ip 的响应时间,kyanos 会将所有相同 remote-ip 的请求响应聚合,最终得出每个 remote-ip 的总耗时的相关指标。
一个更简短的命令形式:
./kyanos stat -m t -g remote-ipm 是 metric 的缩写,t 是 total-time 的缩写,g 是 group-by 的缩写。
TIP
如何过滤流量?
stat 支持所有 watch 命令的过滤选项。
如何分析 stat 命令的结果
如下是输入上述 stat 命令后你会看到的表格: 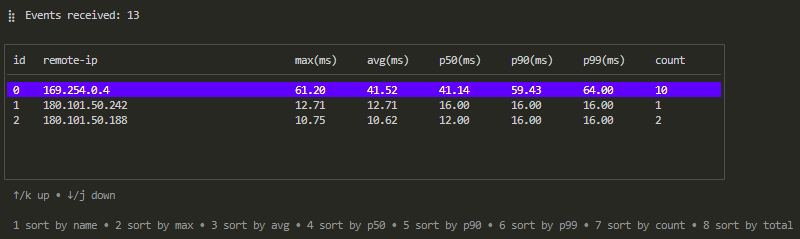
就像 watch 表格的操作方式一样:你可以通过按下数字键对对应的列排序,也可以按 "↑" "↓" 或者 "k" "j" 可以上下移动选择表格中的记录。
但和 watch 表格不同的是表格里的记录,stat 命令是将所有请求响应按照 --group-by 选项聚合的,所以第二列的名称是 remote-ip,其后各列:max、avg、p50 等列表示 --metric 选项所指定指标(在我们这个例子中指 total-time )的最大值、平均值和 P50 等值。
按下 enter 即可进入这个 remote-ip 下具体的请求响应,这里其实就是 watch 命令的结果,操作方式和 watch 完全相同,你可以选择具体的请求响应,然后查看其耗时和请求响应内容,这里不再赘述。
目前支持的指标
kyanos 目前支持通过 --metric 指定的指标如下:
| 观测指标 | short flag | long flag |
|---|---|---|
| 总耗时 | t | total-time |
| 响应数据大小 | p | respsize |
| 请求数据大小 | q | reqsize |
| 在网络中的耗时 | n | network-time |
| 在服务进程中的耗时 | i | internal-time |
| 从 Socket 缓冲区读取的耗时 | s | socket-time |
目前支持的聚合方式
kyanos 目前支持通过 --group-by 指定的指标如下:
| 聚合维度 | 值 |
|---|---|
| 聚合到单个连接 | conn |
| 远程 ip | remote-ip |
| 远程端口 | remote-port |
| 本地端口 | local-port |
| L7 协议 | protocol |
| HTTP PATH | http-path |
| Redis 命令 | redis-command |
| 聚合所有的请求响应 | none |
这些选项记不住怎么办?
如果你记不得这些选项,stat 同样提供了三个选项用于快速分析:
- slow:分析慢请求。
- bigreq:分析大请求。
- bigresp:分析大响应。
同时可以通过 --time 选项指定收集时间,如 --time 10,stat 命令会收集流量 10s:
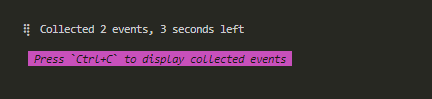
等收集结束或者按下 ctrl+c 提前结束,会出现如下的表格:
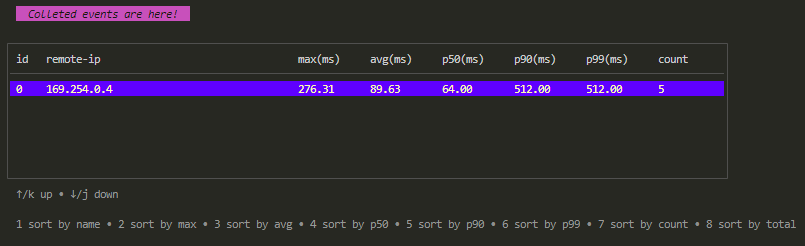
之后的操作方式就相同了。
分析慢请求
抓取 10s 内的流量,快速找到哪一个远程 ip 的 HTTP 请求最慢:
./kyanos stat http --slow --time 10分析大请求和大响应
快速找到哪一个远程 ip 的请求最大:
./kyanos stat http --bigreq快速找到哪一个远程 ip 的响应最大:
./kyanos stat http --bigresp